
背景
PDFに記載されている文字を抽出するパッケージとしてPyPDF2などが有名ですが、PDFによっては
抽出できないものもあります。
目的
今回はGoogle CloudのVision AIの機能の一つである光学式文字認識(OCR)を使ってPDFの表データを抽出したいと思います。また、Vision AIやその他のクラウドサービスにはPythonのAPIを使っています。
結論
下記のPDFの表データをデータフレームにまとめることができました。
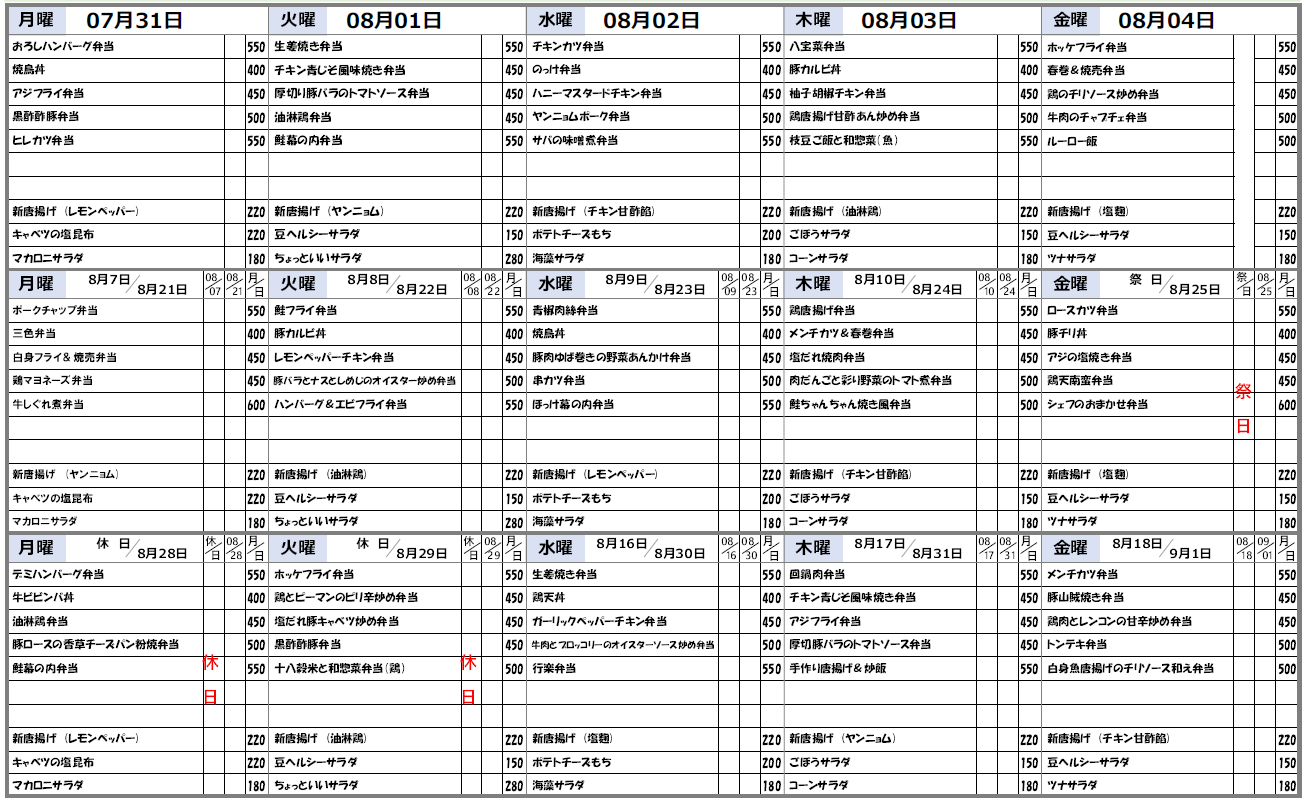
┌────────────┬──────────────────────────────────────────────┬───────┐
│ date ┆ name ┆ price │
│ --- ┆ --- ┆ --- │
│ date ┆ str ┆ i16 │
╞════════════╪══════════════════════════════════════════════╪═══════╡
│ 2023-07-31 ┆ おろしハンバーグ弁当 ┆ 550 │
│ 2023-07-31 ┆ 焼鳥丼 ┆ 400 │
│ 2023-07-31 ┆ アジフライ弁当 ┆ 450 │
│ 2023-07-31 ┆ 黒酢酢豚弁当 ┆ 500 │
│ 2023-07-31 ┆ ヒレカツ弁当 ┆ 550 │
│ 2023-08-01 ┆ 生姜焼き弁当 ┆ 550 │
│ 2023-08-01 ┆ チキン青じそ風味焼き弁当 ┆ 450 │
│ 2023-08-01 ┆ 厚切り豚バラのトマトソース弁当 ┆ 450 │
│ 2023-08-01 ┆ 油林鶏弁当 ┆ 450 │
│ 2023-08-01 ┆ 鮭幕の内弁当 ┆ 550 │
│ 2023-08-02 ┆ チキンカツ弁当 ┆ 550 │
│ 2023-08-02 ┆ のっけ弁当 ┆ 400 │
│ 2023-08-02 ┆ ハニーマスタードチキン弁当 ┆ 450 │
│ 2023-08-02 ┆ ヤンニョムポーク弁当 ┆ 500 │
│ 2023-08-02 ┆ サバの味噌煮弁当 ┆ 550 │
│ 2023-08-03 ┆ 八宝菜弁当 ┆ 550 │
│ 2023-08-03 ┆ 豚カルビ丼 ┆ 400 │
│ 2023-08-03 ┆ 柚子胡椒チキン弁当 ┆ 450 │
│ 2023-08-03 ┆ 鶏唐揚げ甘酢あん炒め弁当 ┆ 500 │
...
│ 2023-09-01 ┆ 鶏肉とレンコンの甘辛炒め弁当 ┆ 450 │
│ 2023-09-01 ┆ トンテキ弁当 ┆ 500 │
│ 2023-09-01 ┆ 白身魚唐揚げのチリソース和え弁当 ┆ 500 │
└────────────┴──────────────────────────────────────────────┴───────┘
内容
(1)環境構築
まずはDockerコンテナを用意すると開発環境の構築が楽かと思います。
version: "3"
services:
lunch-choice:
build:
context: ./
dockerfile: ./dev/Dockerfile
container_name: lunch-choice
volumes:
- ${PWD}/../:/working
working_dir: /working
environment:
PYTHONPATH: /working
TZ: Asia/Tokyo
GOOGLE_APPLICATION_CREDENTIALS: /working/gcp_credentials_key.json
tty: true
このとき、環境変数 GOOGLE_APPLICATION_CREDENTIALS にGoogle Cloudのサービスアカウントから出力したkey(JSON)のパスを指定します。そうすることで、Google CloudやGoogle Workspaceのサービスに簡単にアクセスすることができます。
(2)PDFから文字情報を取得
Vision AIのOCRのAPIを使うために下記のメソッドを作成します。今回はGoogle Cloud Storage(GCS)に保存されているPDFを使います。
from google.cloud import vision
def async_detect_document(
gcs_source_uri: str, gcs_destination_uri: str
) -> None:
"""Cloud Vision APIのOCR機能を使ってPDFから文字情報を取得してJSONファイルとしてGCSに保存
Args:
gcs_source_uri (str): PDFのソースが保存されてるGCSのURI
gcs_destination_uri (str): 文字情報を保存するGCSのURI
"""
# Supported mime_types are: 'application/pdf' and 'image/tiff'
mime_type = "application/pdf"
# How many pages should be grouped into each json output file.
batch_size = 2
client = vision.ImageAnnotatorClient()
feature = vision.Feature(type_=vision.Feature.Type.DOCUMENT_TEXT_DETECTION)
gcs_source = vision.GcsSource(uri=gcs_source_uri)
input_config = vision.InputConfig(gcs_source=gcs_source, mime_type=mime_type)
gcs_destination = vision.GcsDestination(uri=gcs_destination_uri)
output_config = vision.OutputConfig(
gcs_destination=gcs_destination, batch_size=batch_size
)
async_request = vision.AsyncAnnotateFileRequest(
features=[feature], input_config=input_config, output_config=output_config
)
operation = client.async_batch_annotate_files(requests=[async_request])
print("Waiting for the document detection to complete.")
operation.result(timeout=420)
gcs_destination_uri
引数にPDFが保存されているGCSのパス、
gcs_destination_uri
にOCRの結果を出力するGCSのパスを指定してメソッドを実行すると
gcs_destination_uri
に
output-1-to-1.json
というファイルが保存されます。
async_detect_document(
gcs_source_uri=f"gs://lunch-choice/pdf/メニュー表(札幌) 23.8月.pdf",
gcs_destination_uri=f"gs://lunch-choice/json/",
)
(3)文字情報から必要な情報を抽出してデータフレームを作成
(2)で取得した文字情報を読み込みます。
import json
from google.cloud import storage
client = storage.Client()
bucket = client.bucket(bucket_name)
blob_list = [
blob
for blob in list(bucket.list_blobs(prefix="json"))
if not blob.name.endswith("/")
]
output = blob_list[0]
json_string = output.download_as_string()
response = json.loads(json_string)
jsonファイルの中身は↓の感じです。
{'inputConfig': {'gcsSource': {'uri': 'gs://lunch-choice/pdf/メニュー表(札幌) 23.8月.pdf'},
'mimeType': 'application/pdf'},
'responses': [{'fullTextAnnotation': {'pages': [{'property': {'detectedLanguages': [{'languageCode': 'ja',
'confidence': 0.85395265},
{'languageCode': 'en', 'confidence': 0.037915204},
{'languageCode': 'zh', 'confidence': 0.009544642}]},
'width': 842,
'height': 595,
'blocks': [{'boundingBox': {'normalizedVertices': [{'x': 0.02256532,
'y': 0.025210084},
{'x': 0.3361045, 'y': 0.025210084},
{'x': 0.3361045, 'y': 0.11260504},
{'x': 0.02256532, 'y': 0.11260504}]},
'paragraphs': [{'boundingBox': {'normalizedVertices': [{'x': 0.047505938,
'y': 0.026890757},
{'x': 0.28859857, 'y': 0.025210084},
{'x': 0.28859857, 'y': 0.05210084},
{'x': 0.047505938, 'y': 0.053781513}]},
'words': [{'property': {'detectedLanguages': [{'languageCode': 'en',
'confidence': 1}]},
'boundingBox': {'normalizedVertices': [{'x': 0.047505938,
'y': 0.026890757},
{'x': 0.09976247, 'y': 0.025210084},
{'x': 0.09976247, 'y': 0.05210084},
{'x': 0.047505938, 'y': 0.053781513}]},
...
'confidence': 0.9802668}],
'confidence': 0.9617647}],
'text': '月曜 07月31日\nおろしハンバーグ弁当\n焼鳥丼\nアジフライ弁当\n黒酢酢豚弁当\nヒレカツ弁当\n新唐揚げ(レモンペッパー)\n| キャベツの塩昆布\nマカロニサラダ\n月曜\n|ポークチャップ弁当\n三色弁当\n白身フライ & 焼売弁当\n|鶏マヨネーズ弁当\n牛しぐれ煮弁当\n8月7日/\n8月21日\n新唐揚げ (ヤンニョム)\nキャベツの塩昆布\nマカロニサラダ\n月曜\nデミハンバーグ弁当\n牛ビビンバ丼\n油淋鶏弁当\n豚ロースの香草チーズパン粉焼弁当\n鮭幕の内弁当\n休日\n8月28日\n新唐揚げ(レモンペッパー)\nキャベツの塩昆布\nマカロニサラダ\n550 生姜焼き弁当\n400 チキン青じそ風味焼き弁当\n450 厚切り豚バラのトマトソース弁当\n500 油林鶏弁当\n550 鮭幕の内弁当\n08 08 A\n07 21 B\n休\n火曜 08月01日\n220 新唐揚げ (ヤンニョム)\n220 豆ヘルシーサラダ\n180 ちょっといいサラダ\n火曜\n550 鮭フライ弁当\n400 豚カルビ丼\n450 レモンペッパーチキン弁当\n450 豚バラとナスとしめじのオイスター炒め弁当\n600 ハンバーグ & エビフライ弁当\n休 08月\n1日28日\n8月8日/\n220 新唐揚げ(油淋鶏)\n220 豆ヘルシーサラダ\n180 ちょっといいサラダ\n火曜\n550 ホッケフライ弁当\n休日\n8月22日\n220 新唐揚げ(油淋鶏)\n220 豆ヘルシーサラダ\n180 ちょっといいサラダ\n8月29日\n400 鶏とピーマンのピリ辛炒め弁当\n450 塩だれ豚キャベツ炒め弁当\n500 黒酢酢豚弁当\n550 十八穀米と和惣菜弁当 (鶏)\n会社名\n発注者\n休\n18\n水曜 08月02日\n550 チキンカツ弁当\n450 のっけ弁当\n450 ハニーマスタードチキン弁当\n450 ヤンニョムポーク弁当\n550 サバの味噌煮弁当\n220 新唐揚げ (チキン甘酢餡)\n150 ポテトチーズもち\n280 海藻サラダ\n水曜\n08 08 A\n08 22 B\n550\n青椒肉絲弁当\n400 焼鳥丼\n450 豚肉ゆば巻きの野菜あんかけ弁当\n500 串カツ弁当\n550 ほっけ幕の内弁当\n08月\n1日29日\n8月9日\n220 新唐揚げ(レモンペッパー)\n150 ポテトチーズもち\n280 海藻サラダ\n水曜\n550 生姜焼き弁当\n450 鶏天丼\n450 ガーリックペッパーチキン弁当\n8月16日\n8月23日\n220 新唐揚げ(塩麹)\n150 ポテトチーズもち\n280 海藻サラダ\n8月30日\n450 牛肉とブロッコリーのオイスターソース炒め弁当\n500 行楽弁当\n木曜\n550 八宝菜弁当\n400 豚カルビ丼\n450 柚子胡椒チキン弁当\n500 鶏唐揚げ甘酢あん炒め弁当\n550 枝豆ご飯と和惣菜(魚)\n220 新唐揚げ(油淋鶏)\n200 ごぼうサラダ\n180 コーンサラダ\n木曜\n550 鶏唐揚げ弁当\n0808月\n09 23 B\n08月03日\n8月10日\n08 08\n1630 日\n400 メンチカツ & 春巻弁当\n450 塩だれ焼肉弁当\n500 肉だんごと彩り野菜のトマト煮弁当\n550 鮭ちゃんちゃん焼き風弁当\n220 新唐揚げ (チキン甘酢餡)\n200 ごぼうサラダ\n180 コーンサラダ\n木曜\n550 回鍋肉弁当\n400 チキン青じそ風味焼き弁当\n450 アジフライ弁当\n500 厚切豚バラのトマトソース弁当\n550 手作り唐揚げ&炒飯\n8月24日\n8月17日\n220 新唐揚げ(ヤンニョム)\n200 ごぼうサラダ\n180 コーンサラダ\n8月31日\nSHO\nPREMIUM DELIVERY\nLINE公式\n08 08\n550 ホッケフライ弁当\n400 春巻&焼売弁当\n450 鶏のチリソース炒め弁当\n500 牛肉のチャプチェ弁当\n550 ルーロー飯\n金曜 08月04日\n220 新唐揚げ(塩麹)\n150 豆ヘルシーサラダ\n180 ツナサラダ\n金曜\n550 ロースカツ弁当\n1024 日\n祭日\n450 豚刊丼\n450 アジの塩焼き弁当\n500 鶏天南蛮弁当\n500 シェフのおまかせ弁当\n08 08 A\n17 31 B\n220 新唐揚げ(塩麹)\n150 豆ヘルシーサラダ\n180 ツナサラダ\n金曜\n550 メンチカツ弁当\n8月18日\n220\n150\n180\n祭08月\n8月25日 |日25日\n550\n400\n450\n450\n600\n9月1日\n450 豚山賊焼き弁当\n450 鶏肉とレンコンの甘辛炒め弁当\n450 トンテキ弁当\n550 白身魚唐揚げのチリソース和え弁当\n220 新唐揚げ (チキン甘酢餡)\n150 豆ヘルシーサラダ\n180 ツナサラダ\n550\n450\n450\n500\n500\n祭日\n220\n150\n180\n08 09 A\n1801 日\n550\n450\n450\n500\n500\n220\n150\n180'},
'context': {'uri': 'gs://lunch-choice/pdf/メニュー表(札幌) 23.8月.pdf',
'pageNumber': 1}}]}
この情報の文字列をデータフレームに整理します。下のメソッドを作成して単語ごとの座標を取得します。
import polars as pl
from typing import Dict
def response_to_dataframe(document: Dict) -> pl.DataFrame:
"""Cloud Vision AIで取得した文字情報をデータフレームに変換
Args:
document (Dict): Cloud Vision AIで取得した文字情報
Returns:
pl.DataFrame: Cloud Vision AIで取得した文字情報のデータフレーム
"""
# レスポンスから単語(words)と段落ごとの座標を抽出
bounds_word = []
words = []
for page in document["pages"]:
for block in page["blocks"]:
for paragraph in block["paragraphs"]:
for word in paragraph["words"]:
word_tmp = []
for symbol in word["symbols"]:
word_tmp.append(symbol["text"])
bounds_word.append(word["boundingBox"])
word_tmp = "".join(word_tmp)
words.append(word_tmp)
# 文字(text), 左下の座標x, y, 高さ(height)をデータフレームにまとめる
left_bottom = []
for bound in bounds_word:
temp_xs = []
temp_ys = []
for vertice in bound["normalizedVertices"]:
temp_xs.append(vertice["x"])
temp_ys.append(vertice["y"])
left_bottom.append({"x": min(temp_xs), "y": max(temp_ys)})
heights.append(int(max(temp_ys) - min(temp_ys)))
# 文字情報を文字列、左下のx座標、左下のy座標、高さのデータフレームにまとめる
output_df = pl.DataFrame(
{
"text": text,
"left_bottom_x": vertic["x"],
"left_bottom_y": vertic["y"],
"height": height,
}
for (text, vertic, height) in zip(words, left_bottom, heights)
)
return output_df
上の
response_to_dataframe
メソッドを実行すると下記のデータフレームを作成することができます。
df = response_to_dataframe(response["responses"][0]["fullTextAnnotation"])
print(df)
shape: (836, 4)
┌───────┬───────────────┬───────────────┬────────┐
│ text ┆ left_bottom_x ┆ left_bottom_y ┆ height │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ f64 ┆ i64 │
╞═══════╪═══════════════╪═══════════════╪════════╡
│ Daily ┆ 0.047506 ┆ 0.053782 ┆ 0 │
│ Lunch ┆ 0.106888 ┆ 0.052101 ┆ 0 │
│ Menu ┆ 0.180523 ┆ 0.052101 ┆ 0 │
│ 08 ┆ 0.243468 ┆ 0.052101 ┆ 0 │
│ … ┆ … ┆ … ┆ … │
│ 500 ┆ 0.964371 ┆ 0.8302521 ┆ 0 │
│ 220 ┆ 0.964371 ┆ 0.9042017 ┆ 0 │
│ 150 ┆ 0.9655582 ┆ 0.929412 ┆ 0 │
│ 180 ┆ 0.9655582 ┆ 0.954622 ┆ 0 │
└───────┴───────────────┴───────────────┴────────┘
ほぼほぼ、こちらのコードをもとに作っております。ありがとうございます。

(4)データフレームから必要な文字列を抽出
次に(3)のデータフレームから必要な文字列を抽出します。
例えば下図の赤色枠の文字列を抽出したいと思います。
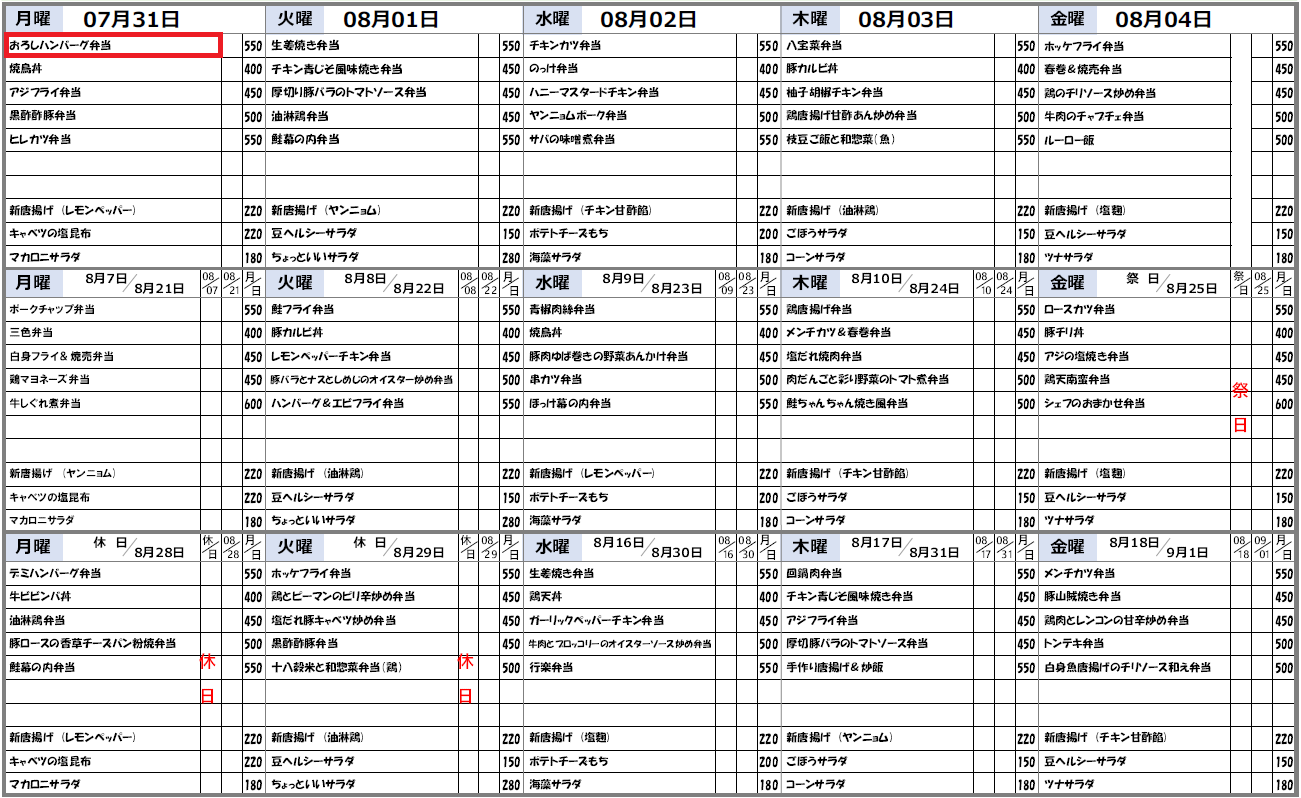
下記が赤枠内の文字列を抽出するメソッドです。
def extract_text_from_region(
input_df: pl.DataFrame,
left_bottom_x: float,
left_bottom_y: float,
width: float,
height: float,
) -> str:
"""領域(left_bottom_x, left_bottom_y, width, height)を指定し,その領域に含まれる文字列を抽出
Args:
input_df (pl.DataFrame): Cloud Vision AIから取得した文字情報
left_bottom_x (float): 文字列の左下のx座標
left_bottom_y (float): 文字列の左下のy座標
width (float): 指定した領域の幅
height (float): 指定した領域の高さ
Returns:
str: 抽出した文字列
"""
output_df = input_df.filter(
(pl.col("left_bottom_x") >= left_bottom_x)
& (pl.col("left_bottom_y") >= left_bottom_y)
& (pl.col("left_bottom_x") <= left_bottom_x + width)
& (pl.col("left_bottom_y") <= left_bottom_y + height)
)
return "".join(output_df["text"].to_list())
extract_text_from_region
メソッドを実行すると「おろしハンバーグ弁当」の文字列を抽出することができます。
str_menu = extract_text_from_region(
input_df=df, left_bottom_x=0.022565, left_bottom_y=0.14958, width=0.15, height=0.03
)
print(str_menu)
'おろしハンバーグ弁当'
この結果を踏まえて下記のように1日分のメニューのデータフレームを作成するメソッドを作成します。
from datetime import datetime, date
def make_menu_for_oneday(
input_df: pl.DataFrame,
left_bottom_x: float,
left_bottom_y: float,
date: date,
) -> pl.DataFrame:
"""一日分のメニュー表の作成
Args:
input_df (pl.DataFrame): Cloud Vision AIから取得した文字情報
left_bottom_x (float): 文字列の左下のx座標
left_bottom_y (float): 文字列の左下のy座標
date (date): メニューが記載されている日付
Returns:
pl.DataFrame: 一日分のメニュー表
"""
# 当日の一番上のメニューを取得
top_menu = extract_text_from_region(
input_df, left_bottom_x, left_bottom_y, 0.15, 0.03
)
# 当日の一番上のメニューが空白の場合は空のデータフレームを作成
if top_menu == "":
output_df = pl.DataFrame(
schema={"date": pl.Date, "name": pl.Utf8, "price": pl.Int16}
)
# 空白でない場合は当日のメニュー表のデータフレームを作成
else:
output_df = pl.DataFrame(
{
"date": date,
"name": [
extract_text_from_region(
input_df, left_bottom_x, left_bottom_y, 0.14, 0.03
),
extract_text_from_region(
input_df, left_bottom_x, left_bottom_y + 0.024, 0.14, 0.03
),
extract_text_from_region(
input_df, left_bottom_x, left_bottom_y + 0.048, 0.14, 0.03
),
extract_text_from_region(
input_df, left_bottom_x, left_bottom_y + 0.072, 0.14, 0.03
),
extract_text_from_region(
input_df, left_bottom_x, left_bottom_y + 0.096, 0.14, 0.03
),
],
"price": [
extract_text_from_region(
input_df, left_bottom_x + 0.17, left_bottom_y, 0.02, 0.03
),
extract_text_from_region(
input_df,
left_bottom_x + 0.17,
left_bottom_y + 0.024,
0.02,
0.03,
),
extract_text_from_region(
input_df,
left_bottom_x + 0.17,
left_bottom_y + 0.048,
0.02,
0.03,
),
extract_text_from_region(
input_df,
left_bottom_x + 0.17,
left_bottom_y + 0.072,
0.02,
0.03,
),
extract_text_from_region(
input_df,
left_bottom_x + 0.17,
left_bottom_y + 0.096,
0.02,
0.03,
),
],
}
).with_columns(
name=pl.col("name").str.replace(r"\|", ""),
price=pl.col("price").str.replace(r"\|", "").cast(pl.Int16),
)
return output_df
make_menu_for_oneday
メソッドを使って、例えば7月31日のメニュー表を作成します。
current_date = datetime.strptime("2023-07-31", "%Y-%m-%d").date()
df_menu_for_oneday = make_menu_for_oneday(
input_df=df,
left_bottom_x=0.02,
left_bottom_y=0.16,
date=current_date
)
print(df_menu_for_oneday)
shape: (5, 3)
┌────────────┬──────────────────────┬───────┐
│ date ┆ name ┆ price │
│ --- ┆ --- ┆ --- │
│ date ┆ str ┆ i16 │
╞════════════╪══════════════════════╪═══════╡
│ 2023-07-31 ┆ おろしハンバーグ弁当 ┆ 550 │
│ 2023-07-31 ┆ 焼鳥丼 ┆ 400 │
│ 2023-07-31 ┆ アジフライ弁当 ┆ 450 │
│ 2023-07-31 ┆ 黒酢酢豚弁当 ┆ 500 │
│ 2023-07-31 ┆ ヒレカツ弁当 ┆ 550 │
└────────────┴──────────────────────┴───────┘
この要領で1週間分、1か月分のメニューを抽出するメソッドを作成すると、下記のように全体のメニュー表を作成することができます。PDFの表データとは形が異なりますが、下記の形の方がその後の処理がしやすくなるかと思います。
shape: (125, 3)
┌────────────┬──────────────────────────────────────────────┬───────┐
│ date ┆ name ┆ price │
│ --- ┆ --- ┆ --- │
│ date ┆ str ┆ i16 │
╞════════════╪══════════════════════════════════════════════╪═══════╡
│ 2023-07-31 ┆ おろしハンバーグ弁当 ┆ 550 │
│ 2023-07-31 ┆ 焼鳥丼 ┆ 400 │
│ 2023-07-31 ┆ アジフライ弁当 ┆ 450 │
│ 2023-07-31 ┆ 黒酢酢豚弁当 ┆ 500 │
│ 2023-07-31 ┆ ヒレカツ弁当 ┆ 550 │
│ 2023-08-01 ┆ 生姜焼き弁当 ┆ 550 │
│ 2023-08-01 ┆ チキン青じそ風味焼き弁当 ┆ 450 │
│ 2023-08-01 ┆ 厚切り豚バラのトマトソース弁当 ┆ 450 │
│ 2023-08-01 ┆ 油林鶏弁当 ┆ 450 │
│ 2023-08-01 ┆ 鮭幕の内弁当 ┆ 550 │
│ 2023-08-02 ┆ チキンカツ弁当 ┆ 550 │
│ 2023-08-02 ┆ のっけ弁当 ┆ 400 │
│ 2023-08-02 ┆ ハニーマスタードチキン弁当 ┆ 450 │
│ 2023-08-02 ┆ ヤンニョムポーク弁当 ┆ 500 │
│ 2023-08-02 ┆ サバの味噌煮弁当 ┆ 550 │
│ 2023-08-03 ┆ 八宝菜弁当 ┆ 550 │
│ 2023-08-03 ┆ 豚カルビ丼 ┆ 400 │
│ 2023-08-03 ┆ 柚子胡椒チキン弁当 ┆ 450 │
│ 2023-08-03 ┆ 鶏唐揚げ甘酢あん炒め弁当 ┆ 500 │
...
│ 2023-09-01 ┆ 鶏肉とレンコンの甘辛炒め弁当 ┆ 450 │
│ 2023-09-01 ┆ トンテキ弁当 ┆ 500 │
│ 2023-09-01 ┆ 白身魚唐揚げのチリソース和え弁当 ┆ 500 │
└────────────┴──────────────────────────────────────────────┴───────┘
まとめ
Vision AIのOCR機能を使ってPDFから表データを抽出しました。
実は、このような泥臭い処理をしなくてもAzureやGoogle Cloudからノーコードで文字情報を取得するサービスがリリースされています。(くろさんに教えて頂きました。)

AIを利用して少しづつ仕事の幅を広げていければいいなと思います。