
背景
バッチ処理などで計算結果のデータフレームをデータベースやファイルに保存したいことがあります。そのときに、データフレームをGoogle Drive上のスプレッドシートに保存すると、無料&手軽にデータベース代わりとして使えます。
目的
ローカル環境およびGoogle Coud上で集計したデータフレームをGoogle Drive上のスプレッドシートに保存する方法を試したいと思います。
結論
Docker環境を構築することで、ローカルとGoogle Cloudで同じシステムを構築することができました。
内容
(1)ローカル環境
①環境構築
Dockerを使うと開発環境の構築が楽になります。
version: "3"
services:
lunch-choice:
build:
context: ./
dockerfile: ./dev/Dockerfile
container_name: lunch-choice
volumes:
- ${PWD}/../:/working
working_dir: /working
environment:
PYTHONPATH: /working
TZ: Asia/Tokyo
GOOGLE_APPLICATION_CREDENTIALS: /working/gcp_credentials_key.json
tty: true
このとき、環境変数 GOOGLE_APPLICATION_CREDENTIALS にGoogle Cloudのサービスアカウントから出力したkey(JSON)のパスを指定します。そうすることで、Google CloudやGoogle Workspaceのサービスに簡単にアクセスすることができます。
②Google Drive上のpreadSheetのデータの読み書き
ローカル環境からスプレッドシートを操作してみます。
まずは、Google APIのPythonライブラリを使って、下記のようなスプレッドシートを操作するクラスを作成します。その中で、スプレッドシートからデータを読み込む、データフレームをスプレッドシートに書き込む、スプレッドシートのデータを削除するメソッドを作成します。
import polars as pl
import google.auth
from googleapiclient.discovery import build
class SpreadSheet:
def __init__(self, sheet_id: str):
self.sheet_id=sheet_id
self.service_sheets = build(
serviceName="sheets", version="v4", credentials=google.auth.default()[0]
)
def read_spreadsheet(self, ranges: str) -> pl.DataFrame:
"""Google Driveに保存されているスプレッドシートからデータを読み込み
Args:
ranges (str): スプレッドシートのシート名:セル範囲
Returns:
pl.DataFrame: スプレッドシートから取得したデータ
"""
# リクエスト
response = (
self.service_sheets.spreadsheets()
.values()
.batchGet(
spreadsheetId=self.sheet_id,
ranges=[ranges],
)
.execute()
)
ranges = response.get("valueRanges", [])
# レスポンスから列名とデータ部分の抽出
lst = ranges[0]["values"][1:]
cols = ranges[0]["values"][0]
# リストの最大の長さに揃える
max_len = max(len(sublist) for sublist in lst)
for sublist in lst:
while len(sublist) < max_len:
sublist.append(None)
return pl.DataFrame(data=lst, schema=cols)
def write_spreadsheet(self, df: pl.DataFrame, ranges: str) -> None:
"""データフレームをスプレッドシートに書き込み
Args:
df (pl.DataFrame): 書き込むデータ
ranges (str): スプレッドシートのシート名:セル範囲
"""
# スプレッドシートのデータを削除
self.remove_spreadsheet(ranges=ranges)
# スプレッドシートに書き込むデータ
data = [
{
"range": ranges,
"majorDimension": "COLUMNS",
"values": [
[col] + df[col].dt.strftime("%Y-%m-%d").to_list()
if col == "date"
else [col] + df[col].to_list()
for col in df.columns
],
}
]
# リクエスト
(
self.service_sheets.spreadsheets()
.values()
.batchUpdate(
spreadsheetId=self.sheet_id,
body={"value_input_option": "USER_ENTERED", "data": data},
)
.execute()
)
def remove_spreadsheet(self, ranges: str) -> None:
"""特定のセル範囲に書かれたスプレッドシートのデータを削除
Args:
ranges (str): スプレッドシートのシート名!セル範囲
"""
# リクエスト
(
self.service_sheets.spreadsheets()
.values()
.clear(
spreadsheetId=self.sheet_id,
body={},
range=ranges,
)
.execute()
)
データを読み書きするスプレッドシートのシートIDを取得します。スプレッドシートを作成し、URLのd/から/editの間の文字列がシートID(下図の白い部分)です。

スプレッドシートにデータを書き込むスクリプトをgoogle_cloud_test.pyと同じディレクトリに作成します。
from google_cloud_test import SpreadSheet
def main():
# インスタンスの作成
ss = SpreadSheet(sheet_id="*******************")
# データフレームの作成
df_write = pl.DataFrame(
{
"foo": [1, 2, 3],
"bar": [6, 7, 8],
"ham": ["a", "b", "c"],
}
)
# スプレッドシートへのデータの書き込み
ss.write_spreadsheet(df=df_write, ranges="シート1!A1:C4")
if __name__ == "__main__":
main()
上記のスクリプトを実行します。
$ python write_spreadsheet.py
スプレッドシートにデータが書き込まれています。
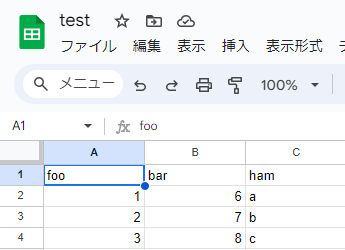
次に、スプレッドシートからデータを読み込むスクリプトをgoogle_cloud_test.pyと同じディレクトリに作成します。
from google_cloud_test import SpreadSheet
def main():
# インスタンスの作成
ss = SpreadSheet(sheet_id="*******************")
# スプレッドシートからデータの読み込み
df_read = ss.read_spreadsheet(ranges="シート1!A1:C4")
print(df_read)
if __name__ == "__main__":
main()
上記のスクリプトを実行するとデータを取得することができます。
$ python read_spreadsheet.py
shape: (3, 3)
┌─────┬─────┬─────┐
│ foo ┆ bar ┆ ham │
│ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str │
╞═════╪═════╪═════╡
│ 1 ┆ 2 ┆ 3 │
│ 6 ┆ 7 ┆ 8 │
│ a ┆ b ┆ c │
└─────┴─────┴─────┘
(2)Google Cloud
ローカル環境で作成したスクリプトをGoogle Cloudで実行します。ローカル環境ではDockerを使って開発環境を構築していますので、Dockerを使うことでGoogle Cloudでも同じ環境でスクリプトを実行することができます。
Google Cloud上では下記のサービスを使ってスクリプトを実行します。開発の流れは下記の通りです。
- GitHubにコードをプッシュ
- Cloud BuildでDockerイメージをビルド
- DockerイメージがArtifact Registryに保存
- Cloud Run Jobsでスクリプトを実行

①GitHubにコードをプッシュ
ローカル環境ではサンプルのプログラムで説明しましたが、Google Cloudでは下記のリポジトリで説明します。
②Cloud BuildでDockerイメージをビルド
下のGoogle Build用のyamlファイルをリポジトリに保存することで、GitHubでプルリクが承認されたコードを自動的にGoogle Cloudに保存することができます。
上のyamlファイル実行するためにGoogle Buildのトリガーを設定します。
| 名前 | lunch-choice |
|---|---|
| リージョン | asia-northeast1 |
| イベント | ブランチにpushする |
| ソース | 第1世代 |
| リポジトリ | interh852/lunch-choice(GitHubアプリ) |
| ブランチ | ^main$ |
| 構成の形式 | Cloud Build構成ファイル |
| ロケーション | リポジトリ |
| Cloud Build 構成ファイルの場所 | gcloud/cloudbuild_prod.yaml |
| 代入変数 | _IMAGE |
| 代入値 | asia-northeast1-docker.pkg.dev/プロジェクト名/リポジトリ名/イメージ名:latest |
③DockerイメージがArtifact Registryに保存
Artifact RegistryにDockerイメージを保存するリポジトリを作成するとCloud Buildでビルドしたイメージが保存されます。
④Cloud Run Jobsでスクリプトを実行
Cloud Run Jobsを使うことでDockerコンテナの特定のスクリプトを実行することができます。
| コンテナイメージのURL | asia-northeast1-docker.pkg.dev/プロジェクト名/リポジトリ名/イメージ名:latest |
|---|---|
| コンテナコマンド | /working/script/run.sh -o update_this_week |
| CPU | 1 |
| メモリ | 512MiB |
まとめ
ローカルでもGoogle Cloud上でもDockerコンテナを実行することができました。